Data Conveyer Introduction
Why is it that data migration projects are so costly and error-prone?
Before answering this question, we need to realize that data alone has no definite meaning. Can the meaning of the data stream below be determined based on data alone?

In order to retrieve the information carried out, we need to know how to interpret the data.
Data is only as good as our ability to interpret it
Let’s start with a trivial example. Imagine a weather forecast announcing a temperature drop below 20 degrees.
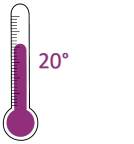 | What does the 20 degrees mean? |
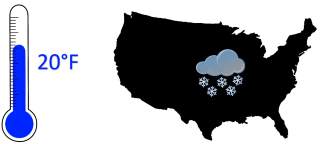 | In America, such forecast most likely indicates the arrival of an arctic air mass. |
 | In Europe however, where temperature is measured in Celsius, this weather forecast would simply convey a relief from a heat wave. |
The consequences of misinterpreting data can be serious.
 | On July 23, 1983, a Boeing 767 operating Air Canada Flight 143 from Ottawa to Edmonton ran out of fuel midair. Miraculously, the plane landed with no casualties. |
The reason for this near disaster quickly became obvious: the plane was refueled with insufficient fuel for the flight. In 1983, Canada was in the midst of converting to the metric system. Details on misinterpretation of refuleling data can be found in many reports of this incident, which is known as Gimli Glider.
So, why is it that data migration projects are so costly and error-prone?
Data comes in different shapes and forms. Some data is easy, or at least straightforward, to interpret. We can readily convert documents, images and other media into just about any imaginable format.
Yet, when it comes to enterprise data, things get more complicated. There are too many proprietary standards and “one-of-a-kind” conventions for data to be interpreted in an unambiguous way. Industry standards, such as XML or EDI help, but they can only reach so far. As a result, data migration projects still involve the same decades old, “tried and true” approach that results in “hard‑wired”, “one of a kind” integration solutions.
Fortunately, thanks to recent advancements in information technology, inexpensive and accurate data migration solutions are now possible.
Data Conveyer Overview
Data Conveyer is a toolkit and a lightweight transformation engine to facilitate real-time data migrations. It harnesses the power of modern, multi-core processors by making extensive use of parallel processing and concurrency. The toolkit enables rapid implementation of a variety of transformations and integration patterns.
Data Conveyer’s architecture conforms to the Extract-Transformation-Load (ETL) paradigm.
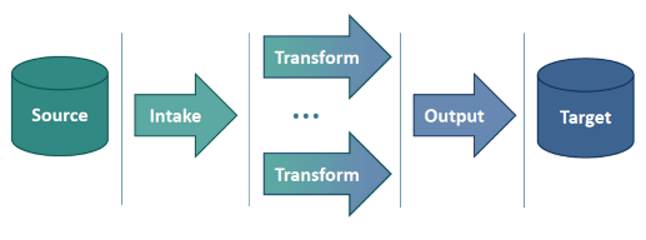
Data Conveyer takes advantage of modern, functional features introduced in recent years into the Microsoft .NET framework, most notably the TPL Dataflow. It harnesses the power of modern, multi-core processors by making extensive use of parallel processing and concurrency. Data Conveyer features a unique, developer‑friendly API, which facilitates rapid creation of sophisticated data migration solutions using a familiar object‑oriented paradigm.
Data Conveyer governs all aspects of data migrations. In addition to the usual mechanisms for input, transformation and output, it handles low-level details, such as data buffering, parallelization, process cancellation, error propagation, and more. Wherever custom logic is needed to address non‑standard parsing, data mapping, routing, formatting, etc., Data Conveyer carefully incorporates supplied code into a complete, fully integrated solution. Such approach enables virtually defect‑free data migration solutions completed in a fraction of the time needed in case of applying traditional techniques. Data Conveyer applies equally to batch processing as well as real‑time solutions.
Main Characteristics of Data Conveyer
- A self-contained executable (DLL library) that does not require any dedicated infrastructure for deployment. It can be deployed on any environment running .NET Framework 4.5 or .NET Standard 2.0. This includes Windows, Linux, Mac OS and other systems.
- Non-blocking, asynchronous execution mode. Operation in progress is cancellable.
- Inherently parallelizable, scalable and production ready.
- Highly configurable, comprehensive, yet intuitive API that accelerates prototyping, development and implementation of various data migration scenarios.
- Native support for a diverse set of data formats, including delimited values, fixed width fields, key-value pairs (keywords), XML, JSON, and X12 (EDI).
- Expandable architecture to support additional data formats and transformation patterns, either natively or using plug-in modules.